텐서플로우에서 TensorRT 사용 방법
텐서플로우(Tensorflow)에서 TensorRT를 사용하는 방법에 대해서 설명드립니다. 텐서플로우 버전 1.7 부터 지원되는 기능 중에서 가장 큰 이슈 중 하나가 텐서플로우와 TensorRT 가 통합된 것일겁니다. 먼저 시스템에 TensorRT를 설치하는 방법에 대해서 설명드리고, 텐서플로우에서 TensorRT를 사용할 수 있도록 소스코드로부터 빌드할 것입니다. 그리고 예제를 통해서 TensorRT를 사용하는 방법에 대해서 알려드리도록 하겠습니다.
소개
어제 NVIDIA 개발자 블로그와 구글 개발자 블로그에서 텐서플로우 1.7 버전부터 TensorRT가 텐서플로우와 통합된다는 내용의 글이 공개가 되었습니다.
TensorRT Integration Speeds Up TensorFlow Inference
Announcing TensorRT integration with TensorFlow 1.7
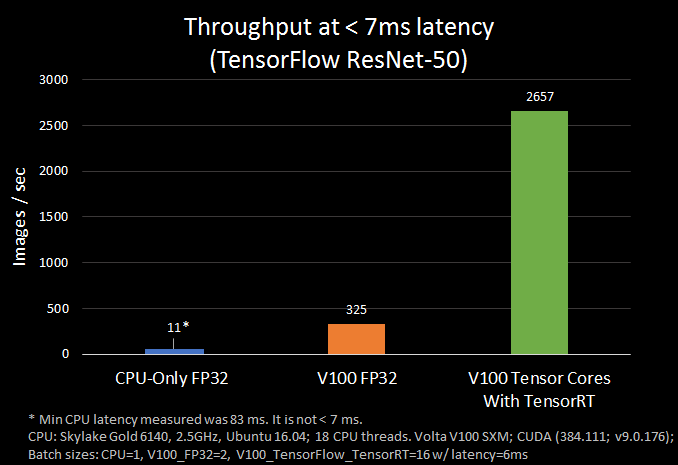
TensorRT는 GPU 상에서 딥러닝 모델을 추론하는 과정에서 대기시간을 최소화하고 처리량을 극대화 할 수 있도록 도와주는 최적화 라이브러리 입니다. ResNet-50 모델으로 텐서플로우 버전만 사용한 경우와 TensorRT 와 함께 사용한 경우를 비교해 봤습니다. 7ms 이하의 대기시간으로 8배 이상으로 빠른 처리량을 나타냈습니다.
기존 그래프에서 최적화 방법을 적용하는데에도 많은 코드가 필요한 것이 아니기 때문에, 환경을 구축하여 예제 코드를 통해서 설명드리도록 하겠습니다.
환경
이 글은 텐서플로우 1.7 버전에서 TensorRT와 통합될 당시 초기 버전의 로우 레벨의 API를 대상으로 작성된 글입니다. 현재 텐서플로우의 안정화 버전은 1.14.0 으로, 이 글에서 사용되는 로우 레벨의 API는 현재 안정화 버전에서도 테스트 되었습니다.
참고로 현재 텐서플로우에서는 로우 레벨의 API를 사용 가능하면서, 동시에 TensorRT의 기능을 쉽고 효율적으로 사용할 수 있도록 상위 API를 지원하고 있습니다. 이점 참고해 주시기 바랍니다.
아래의 글에서 설명드리는 예제는 다음 명령어로 전체 소스코드를 다운 받으 실 수 있습니다.
$ git clone https://hiseon.me/reps/tensorflow-tensorrt.git텐서플로우에서 TensorRT 사용 방법
설치 및 빌드
텐서플로우에서 TensorRT를 사용하기 위해서는 먼저 TensorRT(libnvinfer.so을 포함한 관련파일)가 시스템에 설치되어야 합니다. 설치 준비 단계와 빌드 과정에 대해서 나눠서 설명드리겠습니다.
설치준비
TensorRT는 Tensorflow 버전마다 지원되는 버전이 다릅니다. 따라서 아래의 Support Matrix를 참고하셔서 사용하고자 하시는 TensorRT의 버전을 선택해 주셔야 합니다.
https://docs.nvidia.com/deeplearning/frameworks/tf-trt-user-guide/index.html#prereqs
그리고 TensorRT는 CUDA 패키지 버전에 의존적이기 때문에 다운받고자 하시는 TensorRT는 CUDA 버전과 함께 맞춰주셔야 합니다. TensorRT 설치는 APT Repository에서 설치 하실 수있는데, 이와 관련된 내용은 아래의 페이지를 참고해 주시기 바랍니다.
그리고 TensorRT를 직접 다운 받으신 다음에 설치하고자 하시는 분들은 아래의 페이지에서 직접 다운 받으신 뒤에 설치 하실 수도 있습니다.
https://developer.nvidia.com/nvidia-tensorrt-download
빌드
Nvidia APT Repository를 통해서 TensorRT 가 설치되었다면 텐서플로우 빌드 설정 스크립트에서 자동으로 경로를 찾을 수도 있습니다. 하지만 TensorRT등 라이브러리를 직접 다운 받은 뒤에 설치한 경우면 설치된 경로를 입력해 주시면 됩니다.
Do you wish to build TensorFlow with CUDA support? [y/N]: y
CUDA support will be enabled for TensorFlow.
Do you wish to build TensorFlow with TensorRT support? [y/N]: y
TensorRT support will be enabled for TensorFlow.
Found CUDA 10.0 in:
/usr/local/cuda/lib64
/usr/local/cuda/include
Found cuDNN 7 in:
/usr/lib/x86_64-linux-gnu
/usr/include
Found TensorRT 5 in:
/usr/lib/x86_64-linux-gnu
/usr/include/x86_64-linux-gnu빌드 설정을 하신 다음에 패키지를 빌드 해주시고, 생성된 패키지를 이용하여 텐서플로우를 설치해 주시면 됩니다.
소스코드 빌드 및 설치관련하여 보다 자세한 설정 내용을 확인 하기 위해서는 아래의 내용을 참고해 주시기 바랍니다.
TensorRT 테스트
텐서플로우 1.14 버전 이후에서 TensorRT가 연동되었는지 확인하기 위해서는 아래의 테스트 코드를 실행하면 됩니다.
from tensorflow.compiler.tf2tensorrt.wrap_py_utils import get_linked_tensorrt_version
from tensorflow.compiler.tf2tensorrt.wrap_py_utils import get_loaded_tensorrt_version
compiled_version = get_linked_tensorrt_version()
loaded_version = get_loaded_tensorrt_version()
print("Linked TensorRT version: %s" % str(compiled_version))
print("Loaded TensorRT version: %s" % str(loaded_version))텐서플로우에서 TensorRT가 사용가능하면 아래와 같이 Linked Version과 Loaded Version 을 확인 하실 수 있습니다.
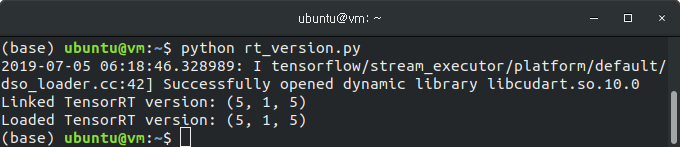
아래와 같은 에러가 발생할 경우 최신 버전의 텐서플로우를 사용하시면서, TensorRT가 사용될 수 있도록 빌드되었는지 확인해 주시기 바랍니다.
ModuleNotFoundError: No module named 'tensorflow.compiler.tf2tensorrt'TensorRT가 사용될 수 있도록 빌드되지 않거나, 로드되지 않았을 경우 TensorRT 예제를 실행하는 과정에서 다음과 같이 TensorRT 버전이 제대로 출력되지 않을 수 있습니다.
TensorRT 버전이 제대로 출력되지 않을 경우, 위의 방법을 사용하여 TensorRT 설치 후 Tensorflow를 빌드해 주시기 바랍니다.
INFO:tensorflow:Running against TensorRT version 0.0.0TensorRT 예제
먼저 라이브러리를 아래와 같이 각각의 모듈별로 import 합니다. 일반적으로 import tensorflow as tf 으로 import 한 다음 tf.placeholder, tf.constant 등과 같이 사용하지만 내부적으로 빌드가 된 것으로 추정됩니다.
import numpy as np
from tensorflow.contrib import tensorrt as trt
from tensorflow.core.protobuf import config_pb2 as cpb2
from tensorflow.python.client import session as csess
from tensorflow.python.framework import constant_op as cop
from tensorflow.python.framework import dtypes as dtypes
from tensorflow.python.framework import importer as importer
from tensorflow.python.framework import ops as ops
from tensorflow.python.ops import array_ops as aops
from tensorflow.python.ops import nn as nn
from tensorflow.python.ops import nn_ops as nn_ops위의 내용과 같이 각각의 모듈을 개별적으로 import 하여 사용된 모듈 이름으로 설명드리도록 하겠습니다.
def get_simple_graph_def():
"""Create a simple graph and return its graph_def."""
g = ops.Graph()
with g.as_default():
a = aops.placeholder(
dtype=dtypes.float32, shape=(None, 24, 24, 2), name="input")
e = cop.constant(
[[[[1., 0.5, 4., 6., 0.5, 1.], [1., 0.5, 1., 1., 0.5, 1.]]]],
name="weights",
dtype=dtypes.float32)
conv = nn.conv2d(
input=a, filter=e, strides=[1, 2, 2, 1], padding="SAME", name="conv")
b = cop.constant(
[4., 1.5, 2., 3., 5., 7.], name="bias", dtype=dtypes.float32)
t = nn.bias_add(conv, b, name="biasAdd")
relu = nn.relu(t, "relu")
idty = aops.identity(relu, "ID")
v = nn_ops.max_pool(
idty, [1, 2, 2, 1], [1, 2, 2, 1], "VALID", name="max_pool")
aops.squeeze(v, name="output")
return g.as_graph_def()
그 다음 간단한 그래프를 정의합니다. CNN 에서 사용되는 기본적인 연산들이 구현되었습니다.
그리고 이어서 입력된 그래프를 이용하여 실행하는 코드를 함께 구현합니다.
def run_graph(gdef, dumm_inp):
"""Run given graphdef once."""
gpu_options = cpb2.GPUOptions(per_process_gpu_memory_fraction=0.50)
ops.reset_default_graph()
g = ops.Graph()
with g.as_default():
inp, out = importer.import_graph_def(
graph_def=gdef, return_elements=["input", "output"])
inp = inp.outputs[0]
out = out.outputs[0]
with csess.Session(
config=cpb2.ConfigProto(gpu_options=gpu_options), graph=g) as sess:
val = sess.run(out, {inp: dumm_inp})
return valGPUOptions 함수에 per_process_gpu_memory_fraction 라는 새로운 파라미터 값이 전달되는 것을 아실 수 있습니다.
per_process_gpu_memory_fraction 값은 TensorRT에서 사용할 수 있는 메모리 공간을 설정하기 위한 값입니다. 예를 들어 이 값이 0.67으로 설정되게 된다면 텐서플로우에서 사용하기 위한 메모리 공간은 67%으로 할당되고 나머지 33%가 TensorRT에서 사용될 수 있도록 남겨지게 됩니다. 이 값은 0에서 1 사이의 값으로 TensorFlow-TensorRT가 처음으로 실행될때 설정되야 합니다.
FP32 정밀도로 최적화
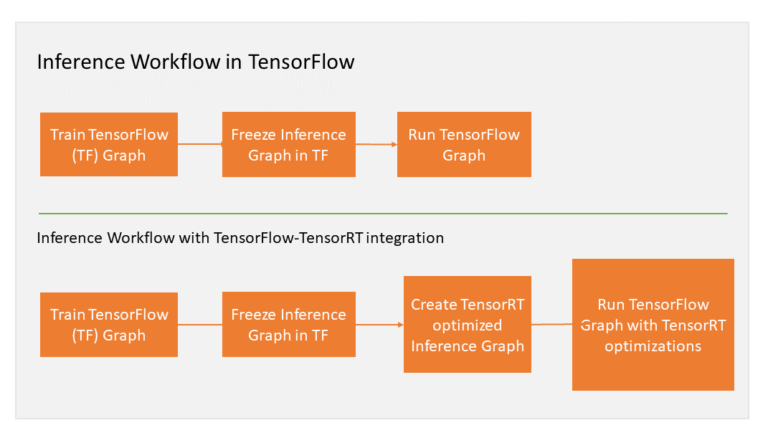
기존 텐서플로우의 그래프를 TensorRT를 이용할 경우 위의 과정을 거처 최적화 하여 실행하게 됩니다.
최적화 된 그래프는 아래의 예제 처럼 trt.create_inference_graph 으로 생성하실 수 있습니다.
inp_dims = (100, 24, 24, 2)
dummy_input = np.random.random_sample(inp_dims)
orig_graph = get_simple_graph_def() # use a frozen graph for inference
# Get optimized graph
trt_graph = trt.create_inference_graph(
input_graph_def=orig_graph,
outputs=["output"],
max_batch_size=inp_dims[0],
max_workspace_size_bytes=1 << 25,
precision_mode="FP32", # TRT Engine precision "FP32","FP16" or "INT8"
minimum_segment_size=2 # minimum number of nodes in an engine
)
o1 = run_graph(orig_graph, dummy_input)
o2 = run_graph(trt_graph, dummy_input)
assert np.array_equal(o1, o2)원래 텐서플로우 그래프와 최적화하여 실행한 결과는 동일 한 것을 알 수 있으실 겁니다.
INT8 정밀도로 최적화
TensorRT에서 지원하는 정밀도 모델은 크게 FP32, FP16 그리고 INT8이 있습니다.
모델에서 사용되는 정밀도에 따라 다르겠지만 필요에 따라서, 기존 모델의 정밀도를 INT8으로 변경한 다음 사용할 수도 있습니다.
기존 정밀도 대신 INT8으로 변환하였을 경우 성능향상이 크게 되겠지만 정밀도는 다소 떨어질 수 있습니다. 전체 과정은 아래와 같습니다.
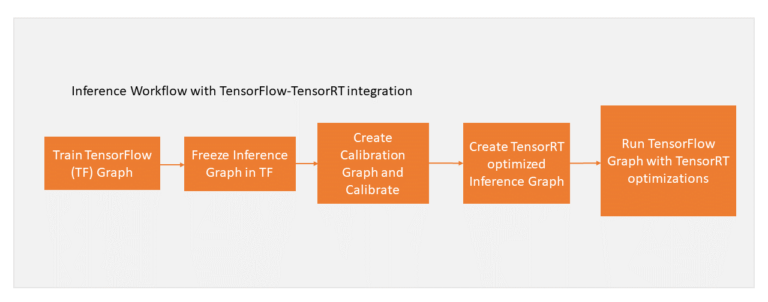
그리고 기존 모델을 INT8로 변환하는 예제는 아래와 같습니다.
inp_dims = (100, 24, 24, 2)
dummy_input = np.random.random_sample(inp_dims)
orig_graph = get_simple_graph_def() # use a frozen graph for inference
int8_calib_gdef = trt.create_inference_graph(
input_graph_def=orig_graph,
outputs=["output"],
max_batch_size=inp_dims[0],
max_workspace_size_bytes=1 << 25,
precision_mode="INT8", # TRT Engine precision "FP32","FP16" or "INT8"
minimum_segment_size=2 # minimum number of nodes in an engine
)
o1 = run_graph(orig_graph, dummy_input)
_ = run_calibration(int8_calib_gdef, dummy_input)
int8_graph = trt.calib_graph_to_infer_graph(int8_calib_gdef)
o5 = run_graph(int8_graph, dummy_input)
assert np.allclose(o1, o5)정밀도 연산에서 차이가 날 수 있기 때문에 결과를 비교하는 함수가 np.array_equal 대신에 np.allclose가 사용된 것을 알 수 있습니다.
하지만 오차범위 내에서 두개의 연산 결과가 동일한 것을 알 수 있습니다. 위에서 사용된 예제 소스코드는 아래의 내용을 참고하였습니다.
https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/tensorrt
공식 버전이 업데이트되었을 경우, 자세한 개발 문서등이 추가될 것으로 생각됩니다.
( 본문 인용시 출처를 밝혀 주시면 감사하겠습니다.)