fastText 사용법 예제
페이스북에서 개발한 자연어 처리 라이브러리인 fastText 사용법에 대해서 설명드립니다. fastText는 Word Embeddings Text Classification 모델을 학습할 수 있습니다.
fastText 이란
fastText는 Facebook’s AI Research (FAIR) 에서 개발된 라이브러리로, Word Embeddings Text Classification 모델을 학습할 수 있습니다. fastText는 word embedding을 위해서 뉴럴 네트워크를 사용하는 것으로 알려졌습니다.
fastText 설치
fastText는 아래의 명령어로 Python 라이브러리를 설치 할 수 있습니다. 그리고 아래의 소스코드를 다운로드 받은 뒤에 바이너리 파일을 사용할 수 있습니다.
fastText는 Python 언어등의 인터페이스를 제공하고 있지만 내부적으로 처리 속도가 빠른 C++ 언어를 이용하여 개발되었습니다.
$ pip install fasttexthttps://github.com/facebookresearch/fastText
fastText 사용법 예제
이글에서 설명드릴 예제는 텍스트를 분류하는 예제에 대해서 설명드리겠습니다. 먼저 아래의 소스코드를 이용하여 fastText를 다운로드 받고 빌드합니다.
$ git clone https://github.com/facebookresearch/fastText
$ cd fastText && makefastText 사용법
fastText 에서 지원되는 옵션은 아래와 같이 fasttext를 실행하면서 –help 옵션을 지정하면 확인이 가능합니다.
$ ./fasttext --help
usage: fasttext
The commands supported by fasttext are:
supervised train a supervised classifier
quantize quantize a model to reduce the memory usage
test evaluate a supervised classifier
test-label print labels with precision and recall scores
predict predict most likely labels
predict-prob predict most likely labels with probabilities
skipgram train a skipgram model
cbow train a cbow model
print-word-vectors print word vectors given a trained model
print-sentence-vectors print sentence vectors given a trained model
print-ngrams print ngrams given a trained model and word
nn query for nearest neighbors
analogies query for analogies
dump dump arguments,dictionary,input/output vectors학습 예제 준비
다음 명령어를 사용하여 학습 데이터를 다운로드 받고, 압축을 해제합니다.
$ wget https://dl.fbaipublicfiles.com/fasttext/data/cooking.stackexchange.tar.gz && tar xvzf cooking.stackexchange.tar.gz
$ head cooking.stackexchange.txt샘플 데이터를 확인하면 아래와 같습니다. __label__ 으로 시작하는 문자열은 라벨을 가리키는 지시어입니다.

모델 학습
학습 데이터를 이용하여 모델을 학습하기 위해서는 아래와 같은 명령어를 사용합니다.
$ ./fasttext supervised -input cooking.stackexchange.txt -output model_cooking -lr 0.5 -epoch 25 -wordNgrams 2모델 테스트
위에서 학습된 모델을 평가하기 위해서는 다음과 같은 명령어를 사용합니다. 편의상 학습데이터로 사용된 파일로 지정하여 테스트 하였습니다.
$ ./fasttext test model_cooking.bin cooking.stackexchange.txt입력된 문자열로 부터 카테고리를 확인하기 위해서는 아래와 같은 명령어를 실행합니다.
$ ./fasttext predict model_cooking.bin -위의 명령어를 실행하면, 입력 대기 상태로 카테고리를 확인하고자 하는 문자열을 입력하면 다음과 같이 결과를 확인 할 수 있습니다.

fastText Python 예제
위의 내용은 fasttext Python 라이브러리로 구현한 내용은 다음과 같습니다.
import fasttext
model = fasttext.train_supervised('cooking.stackexchange.txt', wordNgrams=2, epoch=25, lr=0.5)
# model = fasttext.load_model("model_cooking.bin")
def print_results(N, p, r):
print("N\t" + str(N))
print("P@{}\t{:.3f}".format(1, p))
print("R@{}\t{:.3f}".format(1, r))
print_results(*model.test('cooking.stackexchange.txt'))
print (model.predict("Which baking dish is best to bake a banana bread ?"))
# 3개의 카테고리 정보를 함께 출력
# print (model.predict("Which baking dish is best to bake a banana bread ?", k=3))
model.save_model("model_cooking.bin")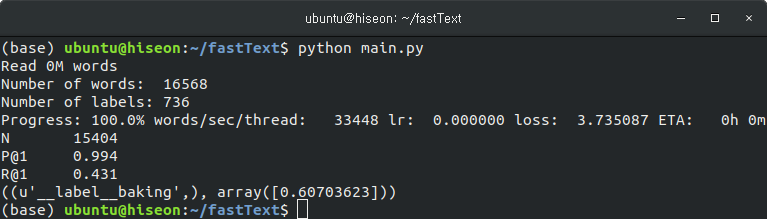
( 본문 인용시 출처를 밝혀 주시면 감사하겠습니다.)