서포트 벡터 머신 SVM(Support Vector Machine) 소개
이번 글에서는 머신러닝 분야 중에서 지도학습 모델로 분류 또는 회귀 분석에 사용되는 서포트 벡터 머신(SVM, Support Vector Machine)을 소개해 드리도록 하겠습니다. 이론과 알고리즘에 대한 주요 설명은 공개된 자료가 많기 때문에 개발자 입장에서 어떻게 SVM을 사용할 수 있는지 중심적으로 설명하도록 하겠습니다.
가장 많이 사용되는 SVM 알고리즘으로는 LIBSVM(A Library for Support Vector Machines)이 있으며, 개발 언어는 C/C++으로 개발되었습니다.
언어는 C/C++으로 개발되었지만 Java, R, Matlab(Octave), Python 등 다양한 언어에서 사용될 수 있도록 인터페이스가 함께 개발되어 제공되고 있으므로 원하시는 언어로 개발을 하시면 됩니다.
아래의 페이지에 접속 하시면 SVM 라이브러리에 대한 소개가 있습니다.
https://www.csie.ntu.edu.tw/~cjlin/libsvm/index.html
페이지 중간 쯔음에 그래픽 인터페이스를 제공하여, 직접 데이터를 입력하여 SVM 알고리즘의 기능을 테스트 해보실 수 있습니다.
테스트는 2가지 형태의 데이터를 나눠서 입력하여 어떻게 SVM에서 분류를 할 수 있는지 확인해 보도록 하겠습니다.
1. 첫 번째 데이터 입력
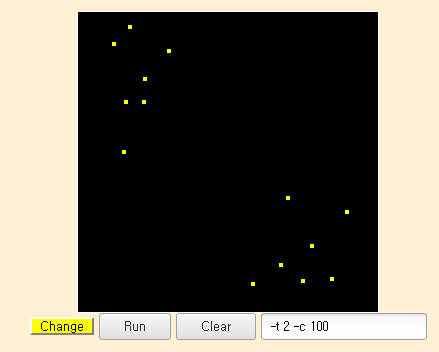
x, y 좌표의 2차원 형태를 갖는 첫 번째 데이터를 마우스를 클릭하여 원하는 위치에 점을 찍습니다.
2. 두번째 데이터 입력
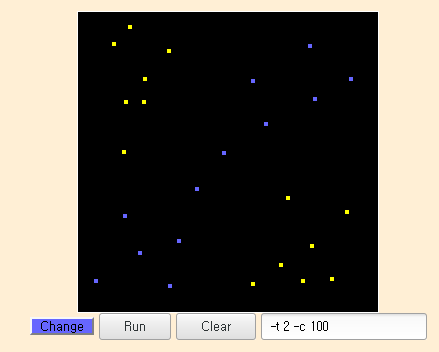
[change] 버튼을 클릭하여 원하시는 색상을 선택 한 다음 마우스를 클릭하여 원하는 위치에 점을 찍습니다.
3. 데이터 분류

[run] 버튼을 클릭하여, SVM 에서 어떻게 데이터를 분류 하는지 확인 할 수 있습니다.
4. 설정
그래픽 인터페이스에서 [-t 2 -c 100] 라는 내용이 SVM 설정 값입니다.
-t는 커널타입의 옵션이며 radial basis 형태의 커널을 사용한다는 의미이고, -c 100은 C-SVC 의 SVM 타입에서 파라미터 C 값을 100으로 설정한 다는 의미입니다.
자세 한 옵션 내용을 아래를 참고하실 수 있습니다.
options:
-s svm_type : set type of SVM (default 0)
0 -- C-SVC
1 -- nu-SVC
2 -- one-class SVM
3 -- epsilon-SVR
4 -- nu-SVR
-t kernel_type : set type of kernel function (default 2)
0 -- linear: u'*v
1 -- polynomial: (gamma*u'*v + coef0)^degree
2 -- radial basis function: exp(-gamma*|u-v|^2)
3 -- sigmoid: tanh(gamma*u'*v + coef0)
-d degree : set degree in kernel function (default 3)
-g gamma : set gamma in kernel function (default 1/num_features)
-r coef0 : set coef0 in kernel function (default 0)
-c cost : set the parameter C of C-SVC, epsilon-SVR, and nu-SVR (default 1)
-n nu : set the parameter nu of nu-SVC, one-class SVM, and nu-SVR (default 0.5)
-p epsilon : set the epsilon in loss function of epsilon-SVR (default 0.1)
-m cachesize : set cache memory size in MB (default 100)
-e epsilon : set tolerance of termination criterion (default 0.001)
-h shrinking: whether to use the shrinking heuristics, 0 or 1 (default 1)
-b probability_estimates: whether to train a SVC or SVR model for probability estimates, 0 or 1 (default 0)
-wi weight: set the parameter C of class i to weight*C, for C-SVC (default 1)
The k in the -g option means the number of attributes in the input data.
다음 글에서는 어떻게 SVM 라이브러리를 이용하여, 소프트웨어를 개발 할 수 있는지 설명해 드리도록 하겠습니다.
( 본문 인용시 출처를 밝혀 주시면 감사하겠습니다.)