텐서플로우 Custom Estimator 예제
Tensorflow Custom Estimator 모델을 만드는 방법에 대해서 설명드립니다. Custom Estimator는 tf.estimator.Estimator의 객체를 생성하여 사용하는 것입니다. 이 내용을 학습하기 위해서 Pre-made Estimator인 DNNClassifier를 뉴럴 네트워크로 만들어볼 예정이며 Iris 데이터를 이용하여 학습하여 모델을 평가하고 추론해보도록 하겠습니다.
Iris 데이터를 Pre-made Estimator인 DNNClassifier으로 학습하는 내용은 아래의 글을 참고해 주시기 바랍니다.
이 글에 사용된 예제 소스코드는 아래의 명령어로 다운 받으실 수 있습니다.
$ git clone https://hiseon.me/reps/tensorflow-iris-example.gitCustom vs. Pre-made
아래의 이미지에서 나타는 것처럼, Custom Estimator의 경우 tf.estimator.Estimator의 인스턴스인 반면에 Pre-made Estimator의 경우 tf.estimator.Estimator를 기반으로 하는 서브클래스들 입니다.
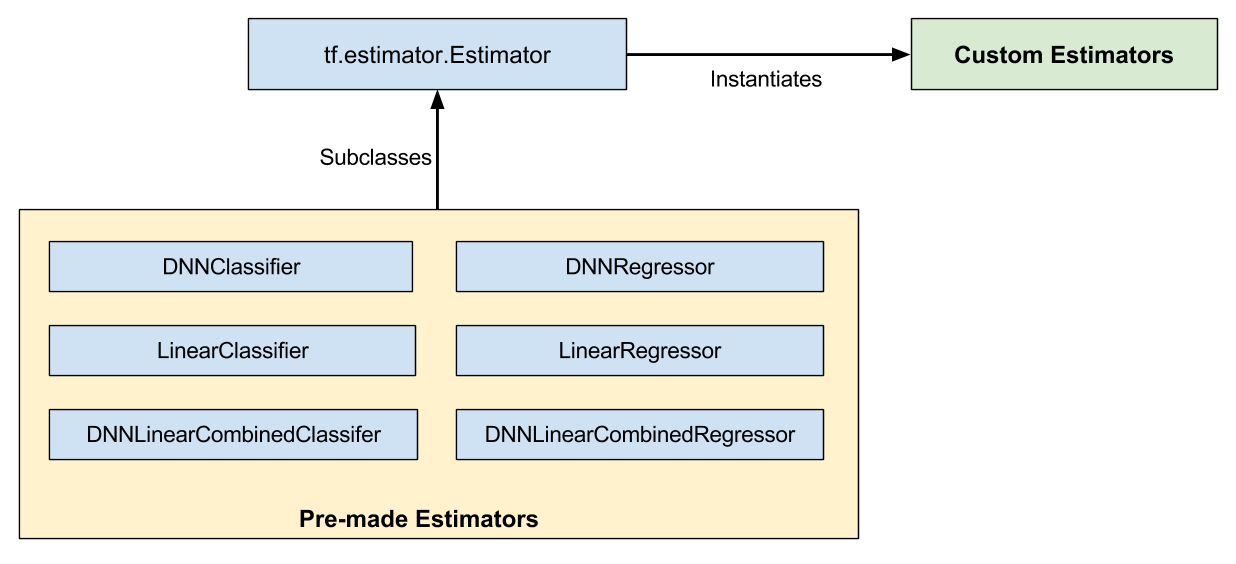
tf.estimator.DNNClassifier 등 Pre-made Estimator의 경우 학습과정과 추론, 평가 과정들이 내부에 구현되어서 쉽게 사용할 수 있는 반면에 세부적으로 모델을 제어하기에 제한이 있습니다. 이러한 문제를 해결하기 위해서 Custom Estimator를 사용하게 됩니다. Custom Estimator는 직접 모델을 학습, 추론, 평가등의 동작을 수행하는 model_fn함수를 tf.estimator.Estimator 객체를 생성할때 전달 하면서 만들 수 있습니다.
이미 만들어진 Pre-made Estimator와 Custom Estimator의 차이는 다음과 같습니다.
- Pre-made Estimators 이미 만들어진 모델 함수로 바로 사용할 수 있습니다.
- Custom Estimators 직접 모델 함수를 작성한 뒤에 사용 할 수 있습니다.
구현된 Pre-made Estimator 모델의 자세한 종류 및 사용법 등은 아래의 페이지를 참고 하실 수 있습니다.
https://www.tensorflow.org/api_docs/python/tf/estimator
모델 함수
tf.estimator.Estimator 객체를 생성하기 위해 가장 중요한 파라미터는 아마 model_fn 으로 전달되는 모델 함수 일 것입니다. 모델 함수 내에서 추론과 학습 그리고 평가 기능이 수행되게 됩니다.
model_fn 함수로 전달되는 모델 함수의 파라미터는 다음과 같으며, tf.estimator.EstimatorSpec 값을 리턴합니다.
- features train, evaluate, predict 함수에서 호출될때 input_fn으로 전달되는 첫 번째 값입니다.
- labels train, evaluate, predict 함수에서 호출될때 input_fn으로 전달되는 두 번째 값입니다.
- mode 학습, 평가 또는 추론여부를 확인 하는 변수로 선택 값입니다.
- params Estimator 객체로 부터 전달되는 파라미터 값으로 선택 값입니다.
- config configuration 객체로 선택 값입니다.
아래는 tf.estimator.Estimator 객체를 생성하기 위해서 정의한 model_fn 함수입니다.
def model_fn(features, labels, mode, params):
net = tf.feature_column.input_layer(features, params['feature_columns'])
for units in params['hidden_units']:
net = tf.layers.dense(net, units=units, activation=tf.nn.relu)
logits = tf.layers.dense(net, units=params['n_classes'], activation=None)
predictions = {'probabilities':tf.nn.softmax(logits, 1)}
if mode == tf.estimator.ModeKeys.PREDICT:
return tf.estimator.EstimatorSpec(mode, predictions = predictions)
loss = tf.losses.sparse_softmax_cross_entropy(labels=labels, logits=logits)
eval_metric_ops = {'accuracy':tf.metrics.accuracy(labels=labels, predictions=tf.argmax(logits, 1))}
if mode == tf.estimator.ModeKeys.EVAL:
return tf.estimator.EstimatorSpec(mode, loss=loss, eval_metric_ops = eval_metric_ops)
# Create training op.
assert mode == tf.estimator.ModeKeys.TRAIN
optimizer = tf.train.AdagradOptimizer(learning_rate=0.1)
train_op = optimizer.minimize(loss=loss, global_step = tf.train.get_global_step())
return tf.estimator.EstimatorSpec(mode, loss=loss, train_op = train_op)mode 변수를 이용하여 학습, 평가, 추론에 맞게 알맞는 tf.estimator.EstimatorSpec 를 리턴하게 됩니다.
예측의 경우, labels 값이 None으로 전달될 수 있기 때문에 가장 먼저 리턴하여 학습과 추론 단계에서 오류가 발생하지 않도록 해야 합니다.
tf.estimator.Estimator 객체 셍생
Estimator 객체는 다음과 같이 feature_columns을 만든 후에, 아래와 같이 생성 할 수 있습니다.
train, test = iris_data.load_data()
train_x, train_y = train
test_x, test_y = test
feature_columns = []
for key in train_x.keys():
feature_columns.append(tf.feature_column.numeric_column(key))
classifier = tf.estimator.Estimator(
model_fn = model_fn,
params = {"n_classes":3, "feature_columns":feature_columns, "hidden_units":[10, 10]}
)tf.estimator.Estimator 객체를 생성하는 방식은 Pre-made Estimator 사용법과 크게 다르지 않는 것을 알 수 있습니다.
모델 학습, 평가, 추론
모델 학습과 평가 그리고 추론은 Pre-made Estimator의 DNNClassifier 방법과 동일하게 사용할 수 있습니다.
classifier.train(input_fn = lambda:iris_data.train_input_fn(train_x, train_y, 100), steps=1000)
result = classifier.evaluate(input_fn = lambda : iris_data.eval_input_fn(test_x, test_y, 100))
print result
predict_x = {
'SepalLength': [5.1, 5.9, 6.9],
'SepalWidth': [3.3, 3.0, 3.1],
'PetalLength': [1.7, 4.2, 5.4],
'PetalWidth': [0.5, 1.5, 2.1],
}
predictions = classifier.predict(input_fn = lambda : iris_data.eval_input_fn(predict_x, None, 100))
for p in predictions:
print p
( 본문 인용시 출처를 밝혀 주시면 감사하겠습니다.)