텐서플로우 Iris 예제 튜토리얼
텐서플로우의 High-Level Tensorflow API의 tf.estimator.DNNClassifier를 이용하여 Iris 데이터셋을 학습하고 평가하는 모델을 학습해 보도록 하겠습니다. 이번 튜토리얼의 목표는 Premade Estimator 모델의 사용방법을 이해하는 겁니다. 이번 글에서는 DNNClassifier 라는 모듈을 사용하고 Iris 데이터셋을 이용할 예정이지만, 이번 튜토리얼을 학습하면 그외의 미리 만들어진 Classifier 및 Regressor 등을 사용하시는데 도움이 될 것이라 생각합니다.

보다 자세한 내용은 아래의 튜토리얼 페이지를 참고해 주시기 바랍니다.
https://www.tensorflow.org/get_started/premade_estimators
그리고 이번 글에서 사용된 예제는 아래 명령어로 전체 소스코드를 다운 받으실 수 있습니다.
$ git clone https://hiseon.me/reps/tensorflow-iris-example.git개요
tf.data.Dataset에 대하여 이해하고 사용할 수 있다는 가정하에 설명드리겠습니다. tf.estimator를 이용하기 위해서는 먼저 tf.data.Dataset 의 모듈을 이해하셔야되는데, tf.data.Dataset에 관해서는 다음글을 참고하시면 됩니다.
설명하는 주요 내용은 아래와 같습니다.
- Iris 데이터셋 : 튜토리얼에 사용될 데이터 구조에 대해 설명드립니다.
- 모델생성 : DNNClassifier 모델을 생성합니다.
- 학습 : 데이터셋을 이용하여 모델을 학습합니다.
- 평가 : 학습된 모델을 평가합니다.
- 추론 : 예제 데이터를 입력하여 결과를 예측합니다.
Iris 데이터셋
데이터셋은 꽃받침(sepal)과 꽃잎(petal)의 사이즈를 기반으로 꽃의 종류를 예측하는 Iris 데이터셋입니다.

https://github.com/tensorflow/models/blob/master/samples/core/get_started/iris_data.py
위의 소스코드를 다운 받은 뒤에 작업 디렉토리에 저장하여 import 하여 사용하도록 하겠습니다. 그리고 아래의 패키지를 설치해 주시기 바랍니다.
$ sudo pip install pandasiris_data.py 소스코드에 나와있듯이 아래와 같이 학습데이터와 테스트 데이터로 나눠져 있습니다.
- http://download.tensorflow.org/data/iris_training.csv
- http://download.tensorflow.org/data/iris_test.csv
컬럼의 순서는 SepalLength, SepalWidth, PetalLength, PetalWidth 그리고 Species 입니다. 그리고 꽃의 종류는 Setosa, Versicolor 그리고 Virginica으로 각각 숫자로 0, 1, 2를 나타내게 됩니다.
예제에서는 iris_data.py를 import하여 사용할 예정이지만, 직접 CSV 파일을 읽어서 처리하실 수도 있을 겁니다. 그럼 본격적으로 코드를 작성해 보도록 하겠습니다. 아래 내용의 코드를 작성합니다.
import tensorflow as tf
import numpy as np
import iris_data
(train_x, train_y), (test_x, test_y) = iris_data.load_data()
print np.shape(train_x)
print np.shape(train_y)train_x, train_y가 각각 (120, 4), (120,)의 형태를 갖습니다. 하지만 실제로는 이 객체는 컬럼 정보가 포함된 pandas 객체로 데이터셋에서 사용되기 위해서 dictionary으로 변환되어 사용되게 될 예정입니다.
모델 생성
Classifier 모델은 Premade Estimator 중의 하나로 Deep Neural Network classifier인 DNNClassifer를 사용하도록 하겠습니다.
모델을 생성하기 위해서는 먼저 모델에서 사용될 feature_column를 정의해야 합니다. 모델에서 어떤 feature가 사용되는지 알려주는 것입니다. 그리고 아래의 파라미터를 전달하면서 classifier 모델을 생성합니다.
feature_columns = []
for key in train_x.keys():
feature_columns.append(tf.feature_column.numeric_column(key))
classifier = tf.estimator.DNNClassifier(
feature_columns = feature_columns,
hidden_units=[10, 10],
n_classes = 3
)분류 모델은 아래의 이미지 처럼 각각 10개의 노드를 갖는 2개의 hidden layer를 구성하였습니다.
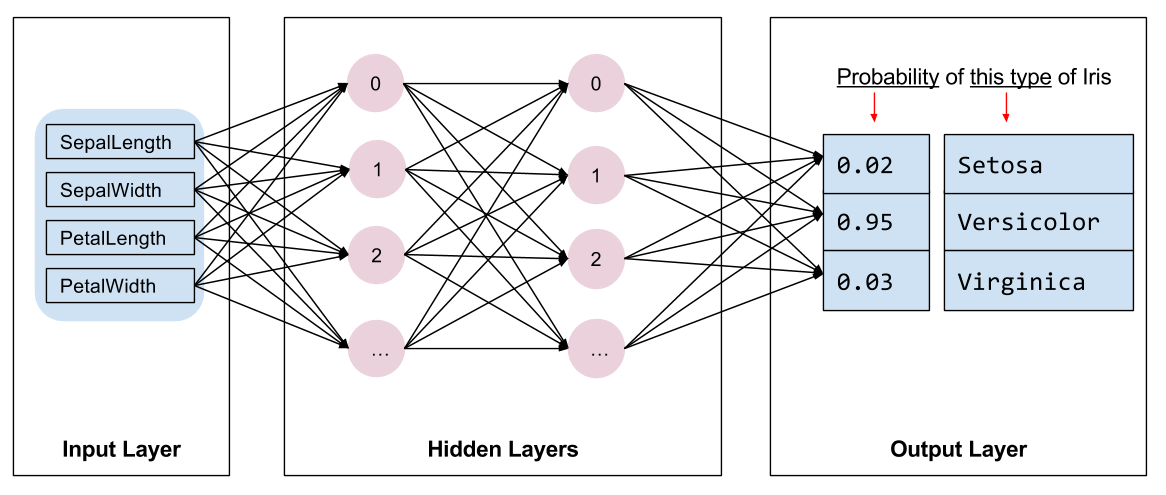
모델 학습
생성한 모델을 학습하기 위해서는 모델로 tf.data.Dataset을 전달해 주는 함수를 만들어야 합니다.
batch_size = 100
steps = 1000
def train_input_fn(x, y, batch_size):
dataset = tf.data.Dataset.from_tensor_slices((dict(x), y))
dataset = dataset.shuffle(1000).repeat().batch(batch_size)
return dataset
classifier.train(input_fn = lambda:train_input_fn(train_x, train_y, batch_size), steps = steps)train_input_fn 라는 함수를 정의한뒤에 3개의 파라미터를 전달하여 실행된 값을 리턴하는 함수룰 lambda식으로 작성하여 전달하였습니다.
그리고 학습 횟수 steps를 지정하면서 classifier.train 함수를 호출하면 학습이 이뤄지게 됩니다.
tf.Session() 등으로 세션을 생성하고 feed_dict 로 데이터를 지정하지 않더라도 바로 학습을 실행할 수 있습니다.
모델 평가
이제 학습된 모델을 평가해 보도록 하겠습니다. 아래의 내용을 추가해 주시면 됩니다.
def test_input_fn(x, y, batch_size):
x=dict(x)
if y is None:
inputs = x
else:
inputs = (x, y)
dataset = tf.data.Dataset.from_tensor_slices(inputs)
dataset = dataset.batch(batch_size)
return dataset
result = classifier.evaluate(input_fn = lambda:iris_data.eval_input_fn(test_x, test_y, batch_size))
print result평가는 classifier.evaluate() 함수를 호출하면서 평가를 할 수 있습니다.
전달되는 파라미터는 input_fn 값으로 평가 데이터 tf.data.Dataset를 리턴하는 함수를 전달해 주면됩니다.
실행된 결과는 아래와 비슷한 내용을 확인 하실 수 있을 겁니다.
{'average_loss': 0.05535654, 'accuracy': 0.96666664, 'global_step': 1000, 'loss': 1.6606961}참고로 위의 예제에서는 tf.data.Dataset 객체를 생성하는 함수를 지정하여 lambda식으로 전달하였습니다. 하지만 아래와 같이 tf.estimator.inputs.numpy_input_fn함수를 이용하여 numpy 객체를 input_fn으로 바로 전달할 수도 있습니다.
classifier.evaluate(input_fn = tf.estimator.inputs.numpy_input_fn(
x = dict(test_x),
y = test_y,
shuffle=False
))데이터 추론
학습된 모델에 데이터를 입력하여, 꽃 종류를 예측할 수 있습니다.
predict_x = {
'SepalLength': [5.1, 5.9, 6.9],
'SepalWidth': [3.3, 3.0, 3.1],
'PetalLength': [1.7, 4.2, 5.4],
'PetalWidth': [0.5, 1.5, 2.1],
}
predictions = classifier.predict(input_fn=lambda:test_input_fn(predict_x, y=None, batch_size=batch_size))
for p in predictions:
print p각각 feature_column 에서 정의된 값을 지정하여, classifier.predict() 함수의 input_fn 값으로 예측하고자 하는 Dataset를 생성하는 함수를 지정해 주면 됩니다. 실행 결과는 아래와 같습니다.
{'probabilities': array([9.9019814e-01, 2.9020819e-05, 9.7728344e-03], dtype=float32), 'logits': array([ 5.20536 , -5.2322865, 0.5870614], dtype=float32), 'classes': array(['0'], dtype=object), 'class_ids': array([0])}
{'probabilities': array([4.7756490e-05, 9.7549963e-01, 2.4452629e-02], dtype=float32), 'logits': array([-5.2070827, 4.7175074, 1.0312953], dtype=float32), 'classes': array(['1'], dtype=object), 'class_ids': array([1])}
{'probabilities': array([1.5067848e-04, 4.8222348e-02, 9.5162696e-01], dtype=float32), 'logits': array([-4.5403256, 1.2281034, 4.210454 ], dtype=float32), 'classes': array(['2'], dtype=object), 'class_ids': array([2])}
( 본문 인용시 출처를 밝혀 주시면 감사하겠습니다.)