텐서플로우 tf.data.Dataset 사용 방법
텐서플로우 dataset 만들기 텐서플로우 Estimator 모델에서 사용되는 데이터 입력 파이프라인인 tf.data.Dataset 예제 사용 방법에 대해서 설명드리도록 하겠습니다. 기존에는 Tensorflow 모델에 직접 feed-dict를 이용하여 값을 전달하였습니다. 하지만 이 방법은 batch 및 shuffle 기능을 직접 구현해야 하며, 실제 모델이 학습하는데 느릴 수 있습니다. 텐서플로우 iris 튜토리얼에서도, tf.data.Dataset 이라는 파이프라인을 이용하여 값을 입력합니다.
데이터를 GPU 메모리로 prefetching 기능이 버전 1.8 부터 제공되게 되는데 이때에도 tf.data.Dataset으로 처리되게 됩니다. 이와 관련해서는 아래의 글을 참고해 주시기 바랍니다.
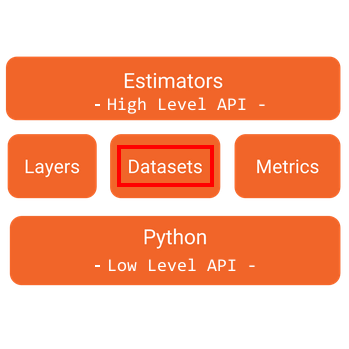
tf.data.Dataset 모듈은 텐서플로우 Python Low Level API 와 상위의 High Level API의 Estimator 모듈 사이에 위치하는 Mid Level의 API입니다. Estimator 의 모델 입력에 사용될 수 있을 뿐만 아니라 직접적으로 데이터 참조에도 사용 될 수 있습니다. 그 아래는 아래의 이미지처럼 텐서플로우 커널이 존재하기 됩니다.

개요
텐서플로우 데이터셋 tf.data.Dataset은 아래와 같이 3가지 부분으로 나눠서 설명드리도록 하겠습니다.
- Dataset 생성 : tf.data.Dataset을 생성하는 것으로 메모리에 한번에 로드하여 사용할 수도 있으며, 동적으로 전달하여 사용할 수도 있습니다.
- Iterator 생성 : 데이터를 조회할때 사용되는 iterator 를 생성합니다.
- 데이터 사용 : 실제 모델에 데이터를 입력하거나, 읽게 됩니다.
텐서플로우 tf.data.Dataset 사용 방법
Dataset 생성
아래와 같이 메모리에 로드된 데이터를 이용하여 Dataset을 생성할 수 있습니다.
x = np.random.sample((10, 2))
dataset = tf.data.Dataset.from_tensor_slices(x)또는 아래와 같이 placeholder를 이용하여 Dataset을 생성하여, 동적으로 데이터를 입력할 수 도 있습니다.
x = tf.placeholder(tf.float32, shape=[None, 2])
dataset = tf.data.Dataset.from_tensor_slices(x)tf.data.Dataset.from_tensor_slices 함수는 tf.data.Dataset 를 생성하는 함수로 입력된 텐서로부터 slices를 생성합니다. 예를 들어 MNIST의 학습데이터 (60000, 28, 28)가 입력되면, 60000개의 slices로 만들고 각각의 slice는 28×28의 이미지 크기를 갖게 됩니다.
Iterator 생성
생성된 Dataset으로 부터 Iterator는 쉽게 생성할 수 있습니다. Dataset의 make_one_shot_iterator() 함수를 호출하면서, tf.data.Iterator를 생성할 수 있습니다. tf.data.Iterator는 아래와 같이 크게 두가지 동작을 제공합니다.
- Iterator.initializer : iterator 상태를 처음 초기화하거나 다시 초기화 하는 동작을 합니다.
- Iterator.get_next() : 다음 항목에 연결되어 있는 tf.Tensor 객체를 리턴합니다.
아래의 코드는 iterator를 생성하고 다음 데이터를 가져오는 동작을 하는 예제입니다.
iterator = dataset.make_one_shot_iterator()
next_element = iter.get_next()데이터 사용
아래와 같이 세션을 실행시켜서, 데이터를 가져와서 사용 할 수 있습니다.
import tensorflow as tf
import numpy as np
x = np.random.sample((10, 2))
dataset = tf.data.Dataset.from_tensor_slices(x)
iterator = dataset.make_one_shot_iterator()
next_element = iterator.get_next()
with tf.Session() as sess:
while True:
try:
print (sess.run(next_element))
except tf.errors.OutOfRangeError:
breakplaceholder를 이용하여 Dataset을 생성하였을 경우, 초기화 할 때에 feed_dict으로 데이터를 전달해야 합니다.
아래는 placeholder를 이용하여 Dataset을 생한 한 뒤에 데이터를 사용하는 방법입니다.
import tensorflow as tf
import numpy as np
data = np.random.sample((10, 2))
x = tf.placeholder(tf.float32, shape=[None, 2])
dataset = tf.data.Dataset.from_tensor_slices(x)
iterator = dataset.make_initializable_iterator()
next_element = iterator.get_next()
with tf.Session() as sess:
sess.run(iterator.initializer, feed_dict = {x:data})
while True:
try:
print (sess.run(next_element))
except tf.errors.OutOfRangeError:
breakMNIST 학습 Dataset 예제
MNIST 데이터를 이용하여 학습 Dataset을 생성해 보도록 하겠습니다.

이전 버전의 텐서플로우에서 사용되는 MNIST 데이터는 아래와 같이 데이터를 읽어서 사용하였습니다.
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data")
하지만 이렇게 MNIST 데이터를 읽게 되면 아래와 같은 안내 메시지가 나타나게 됩니다.
Please use alternatives such as official/mnist/dataset.py from tensorflow/models
기존 tensorflow.examples.tutorials.mnist를 대체 하기 위해서 tensorflow/models의 official.mnist.dataset를 이용할 수 도 있지만, 이번 글에서는 바로 사용 할 수 있는 tf.keras.datasets.mnist 모듈을 사용하도록 하겠습니다.
import tensorflow as tf
import numpy as np
train, test = tf.keras.datasets.mnist.load_data()
train_x, train_y = train
dataset = tf.data.Dataset.from_tensor_slices(({"image":train_x}, train_y))
dataset = dataset.shuffle(100000).repeat().batch(10)
iterator = dataset.make_one_shot_iterator()
next_element = iterator.get_next()
with tf.Session() as sess:
print (sess.run(next_element))위의 예제에서는 tf.data.Dataset.from_tensor_slices() 함수를 호출하면서 이미지 데이터와 라벨 데이터를 함께 전달했습니다. Premade Estimator를 사용하기 위해서는 위와 같이 feature 데이터와 label 데이터가 함께 전달하여 dataset을 생성해야 합니다. 학습 Dataset 생성 예제이기 때문에 아래의 코드가 추가되었습니다.
dataset = dataset.shuffle(100000).repeat().batch(10)위의 코드에서 생성된 Dataset 을 shuffle 함수를 이용하여 섞습니다. shuffle 함수는 고정된 버퍼 크기로 데이터를 섞는데, 데이터가 완전히 랜덤적으로 뒤섞기 위해서는 입력된 데이터 크기보다 큰 수를 입력해 주셔야 합니다.
repeat라는 함수는 데이터셋을 읽다가 마지막에 도달했을 경우, 다시 처음부터 조회하는 함수입니다. 그리고 batch 함수는 데이터를 읽어올 개수를 지정하는 함수입니다.
위의 예제에서는 생성된 Dataset을 iterator의 get_next() 함수를 통해서 값을 읽어들였지만 실제 Estimator 모델에서는 Dataset을 가져오는 함수만 전달해 주면 모델 내부에서 데이터를 읽은 뒤에 사용되게 됩니다. Premade Estimator 모델에서 tf.data.Dataset가 어떻게 사용되는지 관련된 내용은 아래의 글을 참고해 주시기 바랍니다.
( 본문 인용시 출처를 밝혀 주시면 감사하겠습니다.)